|
Hello! I am a first-year MSCS student from Stanford University, specializing in Artificial Intelligence Track. I received my Bachelor of Applied Science in Computer Engineering from University of Toronto with the highest Honor. In the past, I interned at the Vector Institute, working with Prof. Animesh Garg and Prof. Ming Lin on computer vision and robotics. I also spent a summer working with Prof. Luc Van Gool and Dr. Christos Sakaridis at the ETH Zurich Computer Vision Lab, focusing on semantic scene understanding. In addition, I worked with Prof. Shurui Zhou and Prof. Jinghui Cheng on collaboration beyond individuals. Email / Linkedin / Google Scholar / Misc |

|
|
|
|
|

|
Stanford University, CA, United States Master of Science in Computer Science 2024 - 2026 Specialized in Artificial Intelligence CGPA: 4.11/4.00 |

|
University of Toronto, ON, Canada Bachelor of Applied Science 2019 - 2024 Major in Computer Engineering, minor in Artificial Intelligence CGPA: 3.94/4.00 |
|
|
|
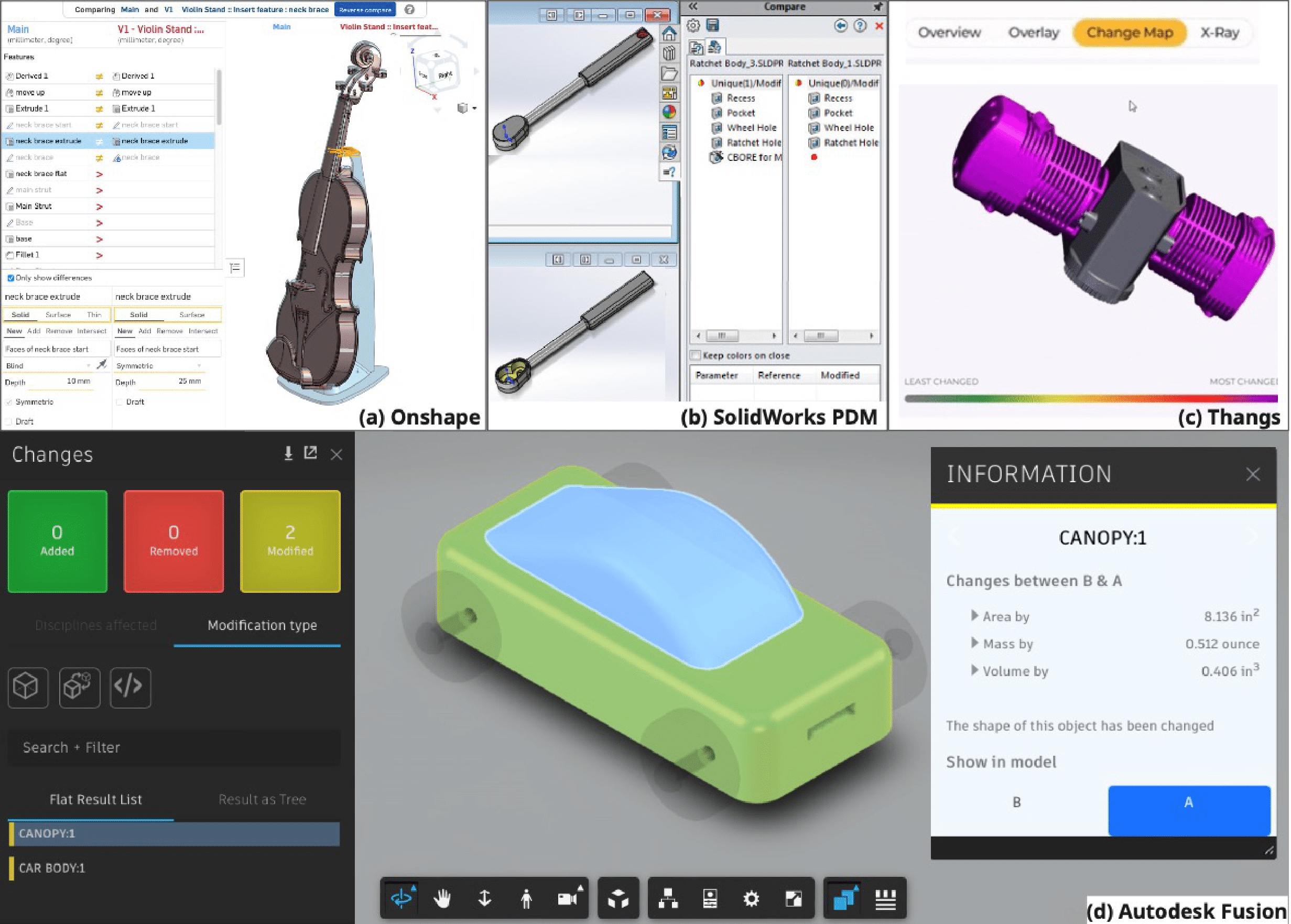
Yuanzhe (Felix) Deng, Shutong Zhang, Kathy Cheng, Alison Olechowski, Shurui Zhou Under review abstract / paper (coming soon...) Version control has been implemented in computer-aided design (CAD) to support mechanical product design by enabling traceability, managing product variation, and supporting collaboration. However, there currently lacks a systematic review of the challenges of performing version control in modern CAD software from a user perspective. In this paper, we mined and analyzed 424 posts and corresponding discussions from online CAD user forums to identify the challenges that CAD users face when using version control for CAD modelling and sharing, concerning the management, continuity, scope, and distribution of versions. We further evaluated the functionalities across three commercially available CAD software with built-in version control capabilities and identified four key challenges that universally exist across all three software. For each key challenge, we discussed corresponding design implications for improving version control in CAD with reference to the state-of-the-art version control solution in software development. This paper concludes with implications for CAD software providers and the CSCW community regarding the future research and development of version control in CAD. |

|
Konstantinos Tzevelekakis, Shutong Zhang, Luc Van Gool, Christos Sakaridis Accepted by the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025 - Oral Presentation abstract / paper / project page Nighttime scenes are hard to semantically perceive with learned models and annotate for humans. Thus, realistic synthetic nighttime data become all the more important for learning robust semantic perception at night, thanks to their accurate and cheap semantic annotations. However, existing data-driven or hand-crafted techniques for generating nighttime images from daytime counterparts suffer from poor realism. The reason is the complex interaction of highly spatially varying nighttime illumination, which differs drastically from its daytime counterpart, with objects of spatially varying materials in the scene, happening in 3D and being very hard to capture with such 2D approaches. The above 3D interaction and illumination shift have proven equally hard to \emph{model} in the literature, as opposed to other conditions such as fog or rain. Our method, named Sun Off, Lights On (SOLO), is the first to perform nighttime simulation on single images in a photorealistic fashion by operating in 3D. It first explicitly estimates the 3D geometry, the materials and the locations of light sources of the scene from the input daytime image and relights the scene by probabilistically instantiating light sources in a way that accounts for their semantics and then running standard ray tracing. Not only is the visual quality and photorealism of our nighttime images superior to competing approaches including diffusion models, but the former images are also proven more beneficial for semantic nighttime segmentation in day-to-night adaptation. |
|
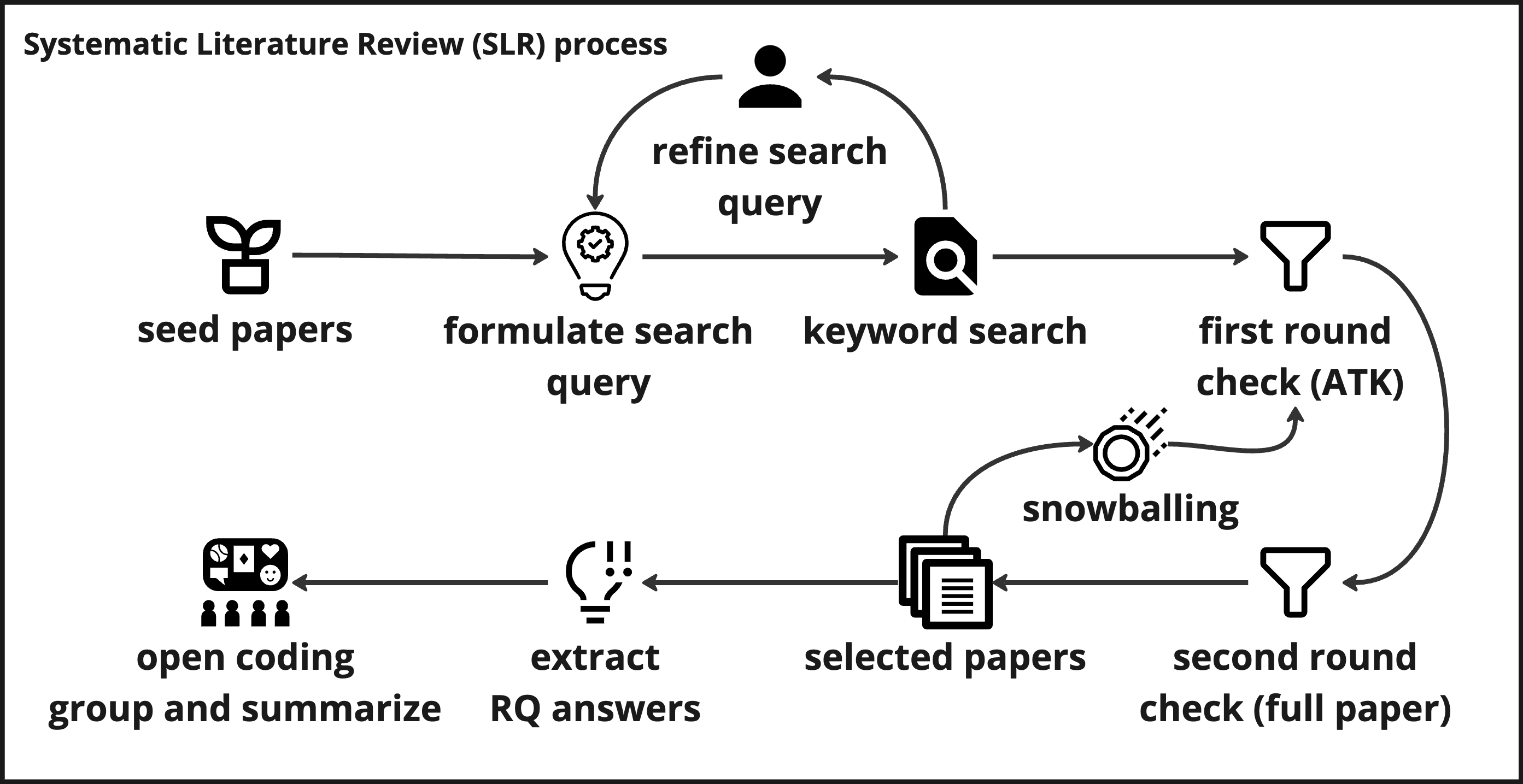
Shutong Zhang, Tianyu Zhang, Jinghui Cheng, Shurui Zhou Accepted by the ACM Conference on Computer-Supported Cooperative Work & Social Computing (CSCW), 2025 abstract / paper / project page Software development relies on effective collaboration between Software Development Engineers (SDEs) and User eXperience Designers (UXDs) to create software products of high quality and usability. While this collaboration issue has been explored over the past decades, anecdotal evidence continues to indicate the existence of challenges in their collaborative efforts. To understand this gap, we first conducted a systematic literature review of 44 papers published since 2005, uncovering three key collaboration challenges and two main best practices. We then analyzed designer and developer forums and discussions on open-source software repositories to assess how the challenges and practices manifest in the status quo. Our findings have broad applicability for collaboration in software development, extending beyond the partnership between SDEs and UXDs. The suggested best practices and interventions also act as a reference for future research, assisting in the development of dedicated collaboration tools for SDEs and UXDs. |
|
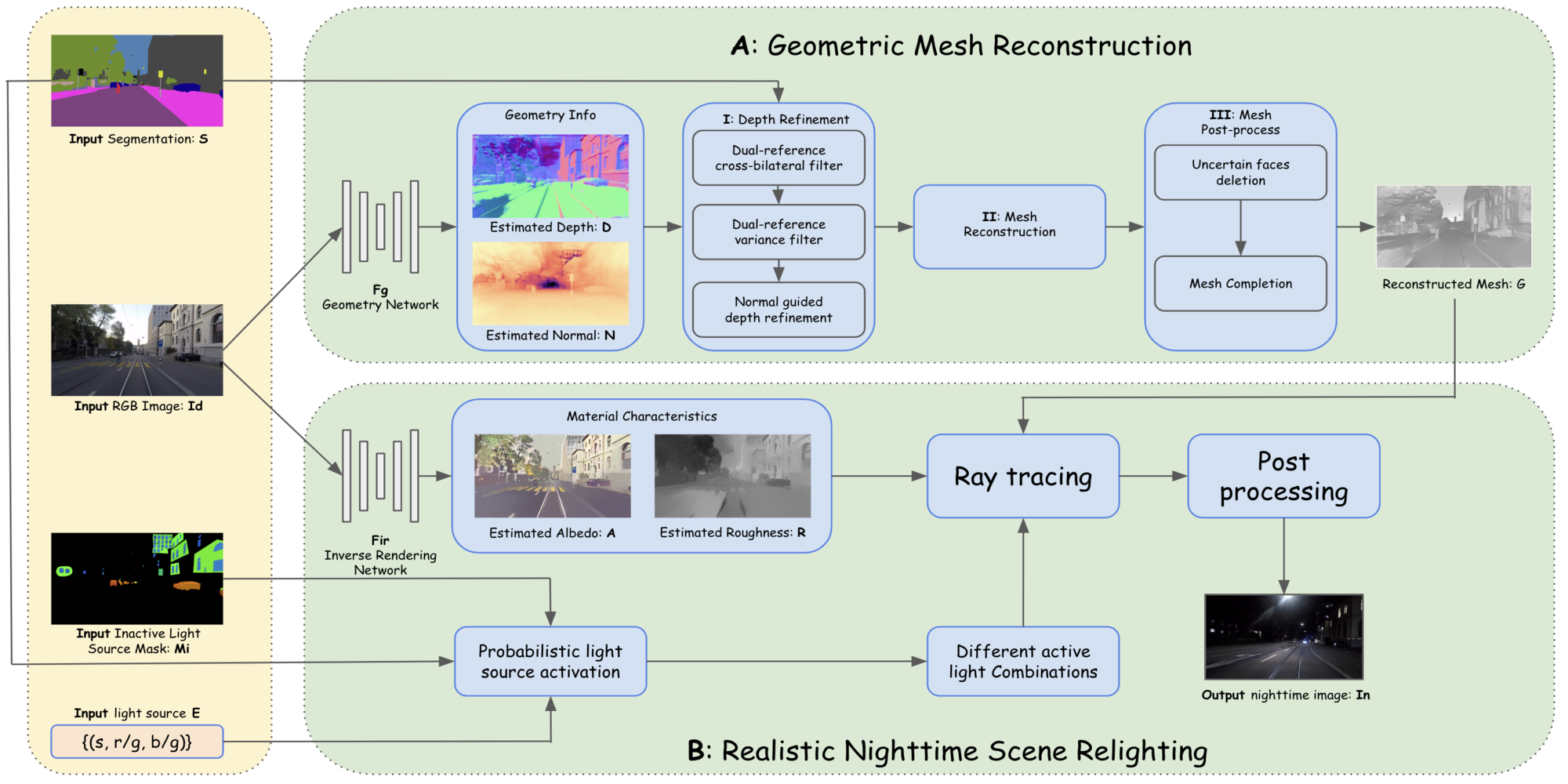
Shutong Zhang Thesis at ETH Zurich Computer Vision Lab abstract / paper / slides Semantic segmentation is an important task for autonomous driving. A powerful autonomous driving system should be capable of handling images under all conditions, including nighttime. Generating accurate and diverse nighttime semantic segmentation datasets is crucial for enhancing the performance of computer vision algorithms in low-light conditions. In this thesis, we introduce a novel approach named NPSim, which enables the simulation of realistic nighttime images from real daytime counterparts with monocular inverse rendering and ray tracing. NPSim comprises two key components: mesh reconstruction and relighting. The mesh reconstruction component generates an accurate representation of the scene’s structure by combining geometric information extracted from the input RGB image and semantic information from its corresponding semantic labels. The relighting component integrates real-world nighttime light sources and material characteristics to simulate the complex interplay of light and object surfaces under low-light conditions. The scope of this thesis mainly focuses on the implementation and evaluation of the mesh reconstruction component. Through experiments, we demonstrate the effectiveness of the mesh reconstruction component in producing high-quality scene meshes and their generality across different autonomous driving datasets. We also propose a detailed experiment plan for evaluating the entire pipeline, including both quantitative metrics in training state-of-the-art supervised and unsupervised semantic segmentation approaches and human perceptual studies, aiming to indicate the capability of our approach to generate realistic nighttime images and the value of our dataset in steering future progress in the field. NPSim not only has the ability to address the scarcity of nighttime datasets for semantic segmentation, but it also has the potential to improve the robustness and performance of vision algorithms under low-lighting conditions. |
|
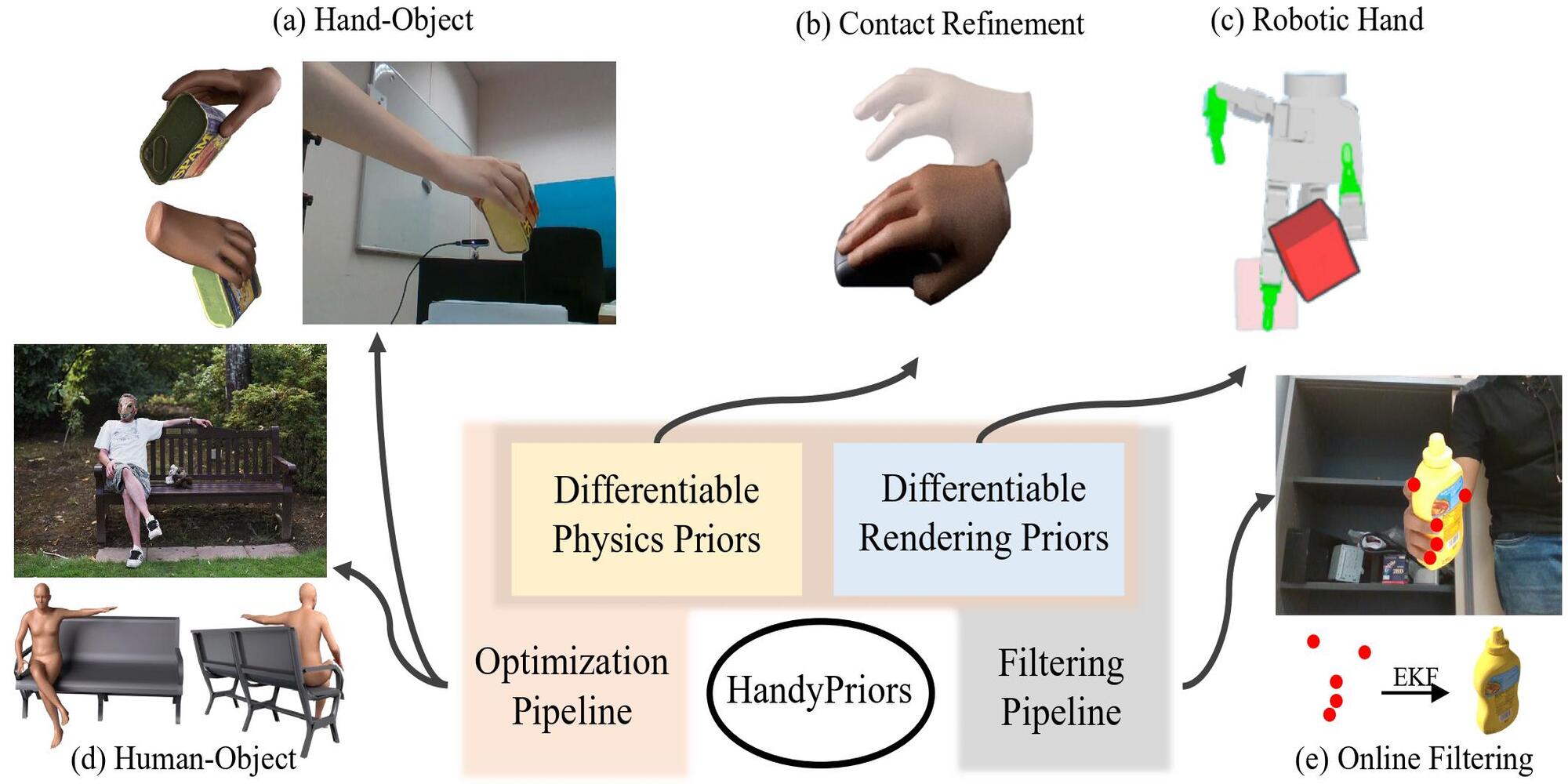
Shutong Zhang*, Yiling Qiao*, Guanglei Zhu*, Eric Heiden, Dylan Turpin, Jingzhou Liu, Ming Lin, Miles Macklin, Animesh Garg Accepted by Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2023 Accepted by IEEE International Conference on Robotics and Automation (ICRA), 2024 abstract / paper / project page Various heuristic objectives for modeling hand- object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HANDYPRIORS, a unified and general pipeline for human- object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmenta- tion masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differen- tiable priors as dynamics and observation models, executes faster. We demonstrate that HANDYPRIORS attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild. |

|
Dylan Turpin, Tao Zhong, Shutong Zhang, Guanglei Zhu, Eric Heiden, Miles Macklin, Stavros Tsogkas, Sven Dickinson, Animesh Garg Accepted by IEEE International Conference on Robotics and Automation (ICRA), 2023 abstract / paper / project page Multi-finger grasping relies on high quality training data, which is hard to obtain: human data is hard to transfer and synthetic data relies on simplifying assumptions that reduce grasp quality. By making grasp simulation differentiable, and contact dynamics amenable to gradient-based optimization, we accelerate the search for high-quality grasps with fewer limiting assumptions. We present Grasp’D-1M: a large-scale dataset for multi-finger robotic grasping, synthesized with Fast- Grasp’D, a novel differentiable grasping simulator. Grasp’D- 1M contains one million training examples for three robotic hands (three, four and five-fingered), each with multimodal visual inputs (RGB+depth+segmentation, available in mono and stereo). Grasp synthesis with Fast-Grasp’D is 10x faster than GraspIt! and 20x faster than the prior Grasp’D differentiable simulator. Generated grasps are more stable and contact-rich than GraspIt! grasps, regardless of the distance threshold used for contact generation. We validate the usefulness of our dataset by retraining an existing vision-based grasping pipeline on Grasp’D-1M, and showing a dramatic increase in model performance, predicting grasps with 30% more contact, a 33% higher epsilon metric, and 35% lower simulated displacement. |
|
|
|
|
Google LLC , United States 2025.6 - Present Software Engineer (Machine Learning) Intern Youtube GenAI for Content Safety |
|
|
Intel Corporation , Canada 2022.5 - 2023.4 Software Engineer Quality and Execution Team: Project Manager and Software Engineer Customer Happiness and User Experience Team: Front-End Developer Core Datapath Team: Compiler Engineer |
|
|

|
PAIR Lab and Vector Institute , Canada 2023.8 - 2024.5 Machine Learning Research Intern Supervisor: Prof. Animesh Garg, with Prof. Ming C. Lin |

|
ETH Zurich Computer Vision Lab , Switzerland 2023.4 - 2023.8 Computer Vision Research Intern Supervisor: Prof. Luc Van Gool and Dr. Christos Sakaridis |

|
Forcolab , Canada 2022.4 - 2023.9 Research Fellow Supervisor: Prof. Shurui Zhou, with Prof. Jinghui Cheng |
|
|
|
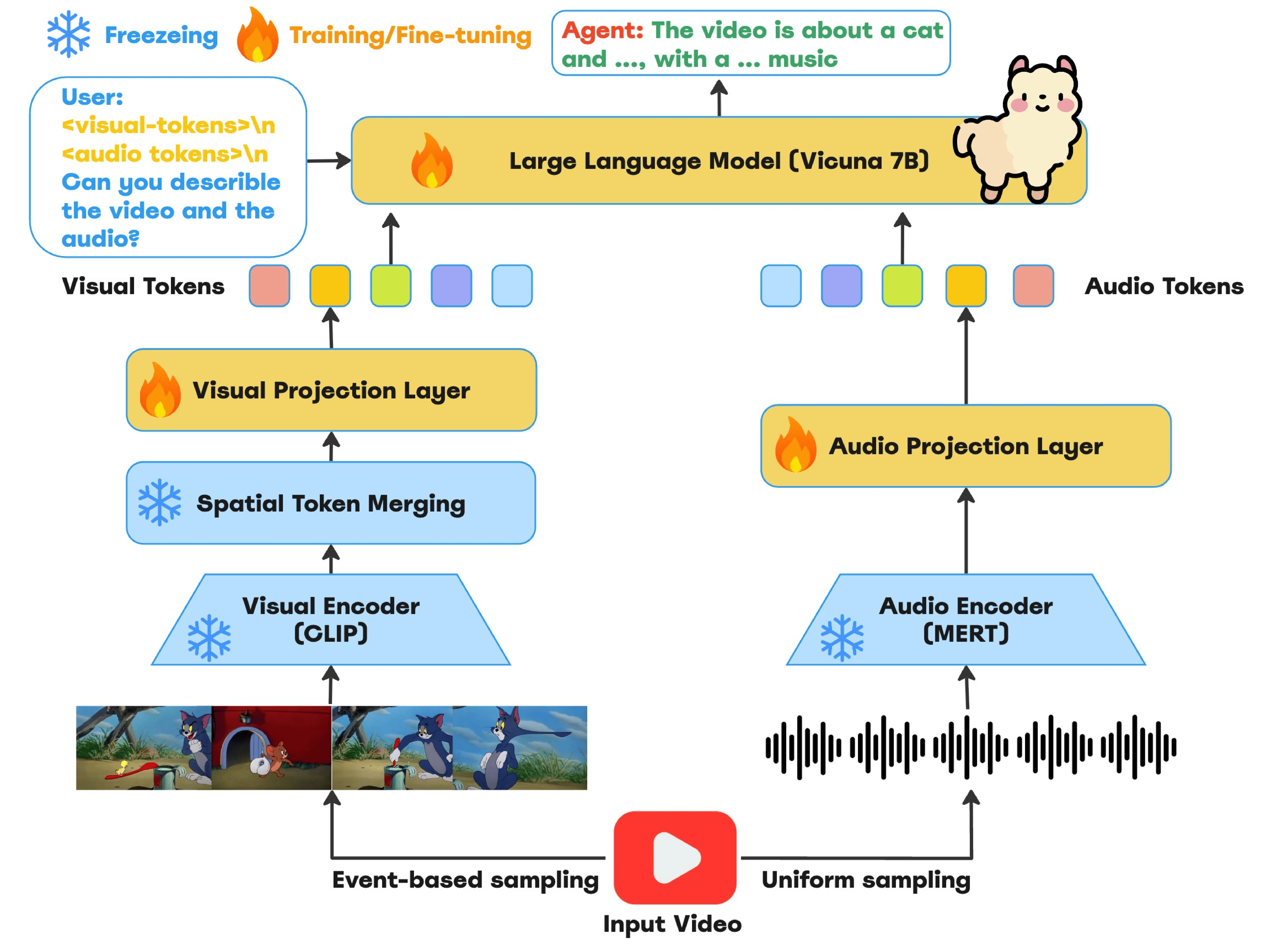
Stanford CS224n Natural Language Processing with Deep Learning Final Project abstract Video summarization is key to managing the ever-growing volume of video content. Personalized summarization, which tailors highlights to individual preferences, offers a more engaging and relevant viewing experience. However, understanding user preferences from video content requires leveraging multiple modalities, including visual, auditory, and textual information. Traditional approaches often fail to integrate these modalities effectively, limiting their ability to create accurate and personalized summaries. In this project, we introduce a multi-modal learning framework that combines information from both video and audio sources to create personalized video summaries. Evaluation results on benchmark datasets demonstrate that our approach achieves competitive performance relative to state-of-the-art models. Overall, our framework advances video summarization by incorporating diverse modalities to produce contextually rich and personalized summaries, offering promising directions for future research in dynamic multimedia environments. |
|
Stanford CS224r Deep Reinforcement Learning Final Project abstract Large language models (LLMs) have demonstrated strong performance across a range of tasks, including text generation, image classification, and reasoning. To better align these base models with specific user needs, fine-tuning plays a crucial role. In this project, we aim to improve a large language model’s instruction following and math reasoning abilities through fine-tuning. Specifically, we work on Qwen-2.5-0.5B model, apply Supervised Fine-Tuning (SFT) and incorporate reinforcement learning techniques, including Direct Preference Optimization (DPO) and REINFORCE Leave-One-Out (RLOO). For the instruction following task, we use the SmolTalk dataset and the UltraFeedback dataset for SFT and DPO, respectively. We also incorporate Reinforcement Learning from AI Feedback (RLAIF) for preference scoring. For the math reasoning task, we use the WarmStart dataset and the Countdown dataset for SFT and RLOO, respectively. To further boost the accuracy, we use a calculator tool during both training and inference time. |
|
|
|
|
|
Template borrowed from here. |